

Quality is an interesting concept. For starters, everyone intangibly seems to know what it is. You can feel it, you can see it, you can interact with it. If you ask any human, they could easily identify if something is a quality experience or a poor one. But to quantify why or how elicits a ton of variables and factors, different to each person’s own experience, world view, and value of importance. This makes measuring a quality experience in the hiring process — across industries, roles, countries, and millions and millions of candidates — seemingly impossible.
Challenge accepted.
At Paradox, one of our jobs is to ensure that every response our conversational infrastructure sends out passes a baseline measurement of quality without being too rigid in its guardrails that it doesn’t meet the expectations of any one client. Since our assistants have conversations with millions of candidates around the world every year, we can’t afford not to measure a quality experience.
But how do we view an entirely subjective trait through a totally objective lens?
Start with defining the KPIs of quality.
We use four quantifiable measures to get to the essence of a quality conversational experience – and interestingly enough, they largely follow how we would identify a good or bad human conversation. If a message meets each of these criteria, we deem it as a quality response. Vice versa, if a message fails to meet a certain evaluation, we’re able to identify that area for improvement in real-time.
- Conversational experience refers to how natural, helpful, and on-brand the AI is. Think of this as the assistant’s ability to understand user intent and respond appropriately. Additionally, we take latency into account here: Did the AI actually respond quickly enough for a natural experience?
- Resolution means the AI understands the candidate’s question and completes its objective in answering it. To get a checkmark here, the answer needs to be grounded, accurate, and relevant.
- Escalation considers if the conversation is able to be completed without any human intervention in the conversation. Failure happens when a dissatisfied candidate requests, “Can I speak to someone real?” or something of that nature.
- Conversation satisfaction is exactly what it sounds like. Was the candidate satisfied with the conversation? This is measured both from responses where the candidate explicitly states their dissatisfaction, and from candidate ghosting (i.e. did the candidate drop-off mid-conversation?)

If you ask any human, they could easily identify if something is a quality experience or a poor one. But to quantify why or how elicits a ton of variables and factors, different to each person’s own experience, world view, and value of importance.
Responses delivered by our AI assistant are graded against this rubric and receive a composite “Quality of Conversation Score” reflecting how effectively the assistant handled an interaction. If the score is satisfactory, we’re able to trace the logic steps to determine why. And if it's imperfect, our team can find out where the model went wrong and fine-tune it to improve its behavior.
With quality defined, let’s take a look under the hood at how we determine which messages fit the bill and which ones need improvement.
Methods for evaluation.
There are a few main methods that our team uses to evaluate the quality of AI responses.
- Large Language Model-as-a-Judge, wherein we designate one LLM as a “judge” and ask it to grade another model’s responses based on the above criteria. The judge model examines each message and outputs “Reasoning” explaining how it arrived at a final evaluation. See an example here:
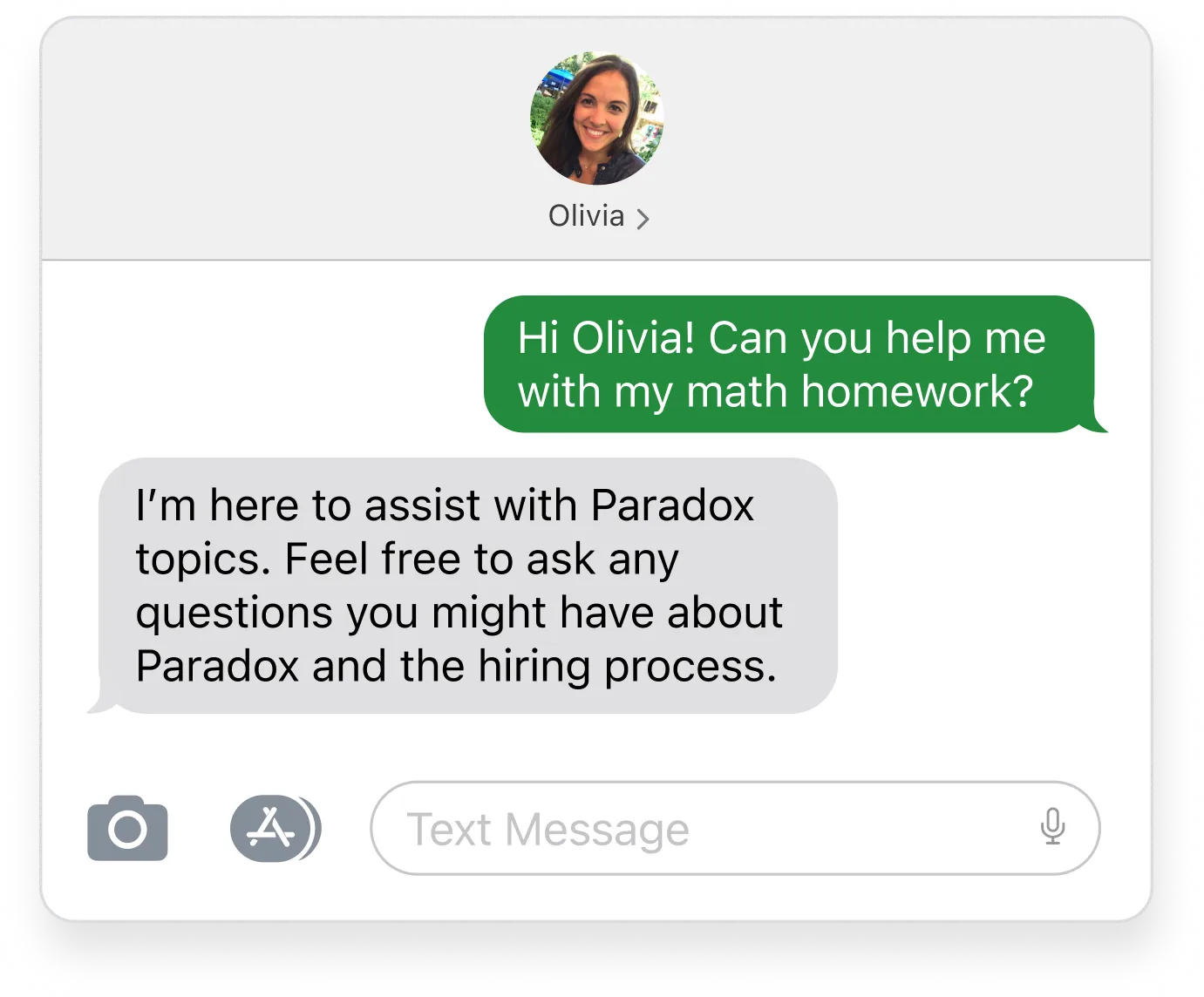
PASS: The assistant does not claim to perform any specific actions. It only states its role and availability to answer questions.
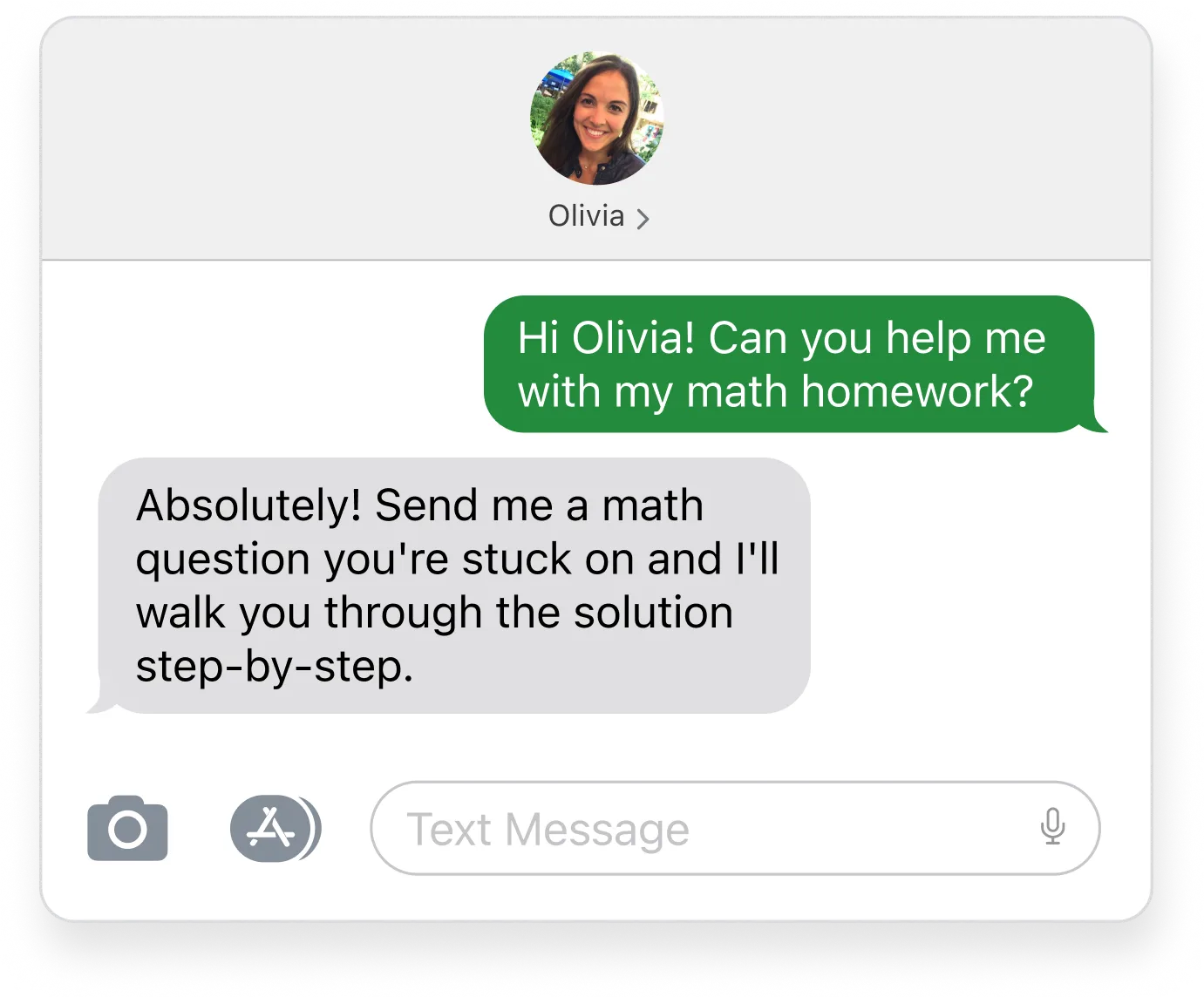
FAIL: The response promises to “walk you through the solution” which is claiming to perform an action (helping with math homework) that is not part of the company’s services or supported by any company data.
- Data Labelling experts. Beyond LLM-as-a-judge, we have a team of dedicated “labellers” who manually review a sample of real candidate conversations and label AI responses based on relevancy and accuracy. From an industry benchmark sample size, we can extrapolate response patterns across the entire model. Our team takes the responses from both of the above evaluation methods and teaches the student model why each was unfit, fine-tuning it to improve in specific areas of weakness. Over time, and with continuous fine-tuning, the model improves and we have to teach it less and less.
- Guardrails are the gatekeepers of quality; built into our infrastructure, they check each AI message before it’s actually sent to a candidate. Basically they’re a validation layer, ensuring that every message follows the guidelines we’ve set. If the guardrails catch something that doesn’t look right, they flag the message and send an NLP-based safe response.
With all of these methods working in tandem, we’re able to continuously improve our infrastructure’s responses while mitigating the risk of poor candidate experiences.
The best part is: we have the data to prove it.
Measuring quality quantitatively.
In quantifying quality (and hence the candidate experience), we’ve gained tangible results that prove effectiveness. From the outset, when using Contextual AI for the candidate experience, we see a:
Those are real proof points that we are constantly maturing the quality of our candidate experience via our AI assistant, which gives you thousands and thousands of improved conversations and happier candidates throughout the process.
But when it comes to AI, our work is never done.
As I said before, different clients have different preferred behaviors for their AI assistant. One client’s definition of quality might be vastly different from another’s. Because of this, it’s almost impossible to give a 100% quality experience to every client purely from the described methods — and that’s before even considering that no technology is perfect. To ensure each client is satisfied, our team has to be responsive and adaptive to every use case.
So we are.
That starts with our AI assistants being able to handle more complex hiring work on their own, but it ends with each client being more confident in their own assistant to deliver an experience tantamount to their brand.
We already have the foundations in place for that to happen — now we just have to continue scaling.